Caffeine高性能缓存库
Caffeine高性能缓存库
Caffeine简介
Caffeine是基于JAVA 1.8 Version的高性能缓存库。Caffeine提供的内存缓存使用参考Google guava的API。Caffeine是基于Google Guava Cache设计经验上改进的成果。
并发测试官方性能比较:
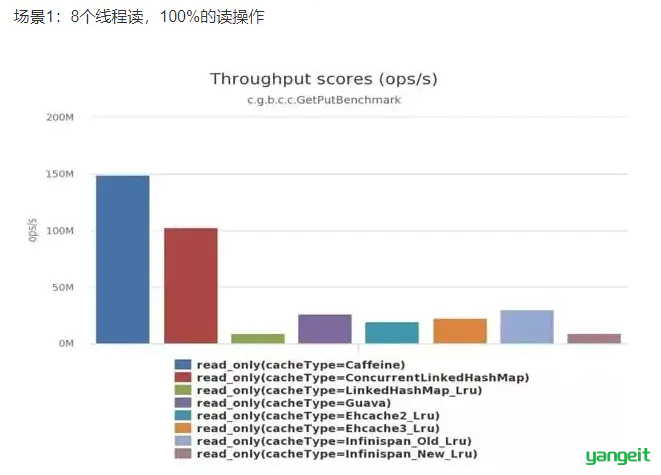
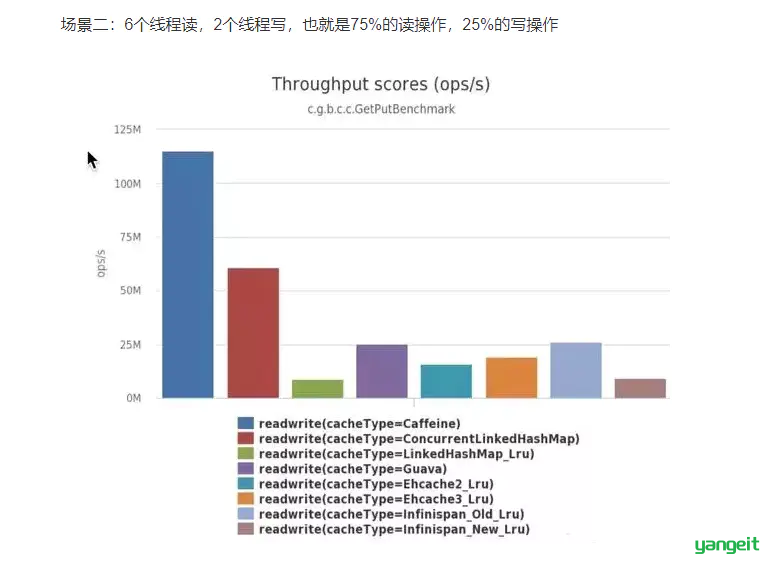
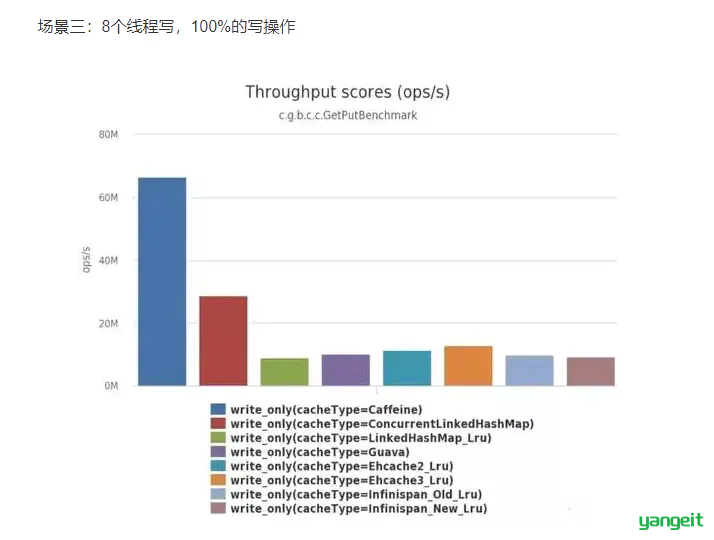
可以清楚的看到Caffeine效率明显的高于其他缓存。
Caffeine可以通过建造者模式灵活的组合以下特性:
- 通过异步自动加载实体到缓存中
- 基于大小的回收策略
- 基于时间的回收策略
- 自动刷新
- key自动封装虚引用
- value自动封装弱引用或软引用
- 实体过期或被删除的通知
- 写入外部资源
- 统计累计访问缓存
填充策略(Population)
Caffeine提供了3种加载策略:手动加载,同步加载,异步加载
手动加载
- cache手动

- cache手动
同步加载
- loadingCache同步

- loadingCache同步
异步加载
- AsyncLoadingCache 是 LoadingCache 的变体, 可以异步计算实体在一个线程池(Executor)上并且返回 CompletableFuture.

- AsyncLoadingCache 是 LoadingCache 的变体, 可以异步计算实体在一个线程池(Executor)上并且返回 CompletableFuture.
驱逐策略(Eviction)
提示
- 基于大小
- 基于缓存容量
- 基于权重
- 基于时间
- 实体被访问之后,在实体被读或被写后的一段时间后过期

- 基于写之后,在实体被写入后的一段时间后过期
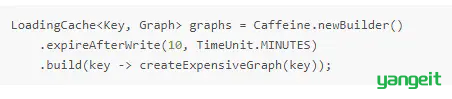
自定义策略Expiry,可以自定义在实体被读,被更新,被创建后的时间过期。

基于引用 java种有四种引用:强引用,软引用,弱引用和虚引用,caffeine可以将值封装成弱引用或软引用。
软引用:如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。
弱引用:弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存

- 自动刷新

在写后的持续时间过后,调用createExpensiveGraph刷新
监控(Monitor)

通过使用Caffeine.recordStats(), 可以转化成一个统计的集合. 通过 Cache.stats() 返回一个CacheStats。CacheStats提供以下统计方法
hitRate(): 返回缓存命中率
evictionCount(): 缓存回收数量
averageLoadPenalty(): 加载新值的平均时间
移除通知(Notify)
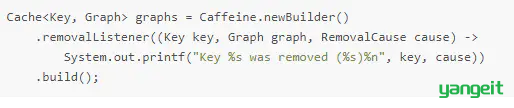
通过removalListener添加实体移除监听器
淘汰算法
Window TinyLFU(W-TinyLFU)算法将sketch作为过滤器,当新来的数据比要驱逐的数据高频时,这个数据才会被缓存接纳。这个许可窗口给予每个数据项积累热度的机会,而不是立即过滤掉。这避免了持续的未命中,特别是在突然流量暴涨的的场景中,一些短暂的重复流量就不会被长期保留。为了刷新历史数据,一个时间衰减进程被周期性或增量的执行,给所有计数器减半。
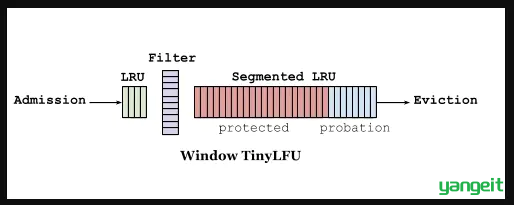
对于长期保留的数据,W-TinyLFU使用了分段LRU(Segmented LRU,缩写SLRU)策略。起初,一个数据项存储被存储在试用段(probationary segment)中,在后续被访问到时,它会被提升到保护段(protected segment)中(保护段占总容量的80%)。保护段满后,有的数据会被淘汰回试用段,这也可能级联的触发试用段的淘汰。这套机制确保了访问间隔小的热数据被保存下来,而被重复访问少的冷数据则被回收。
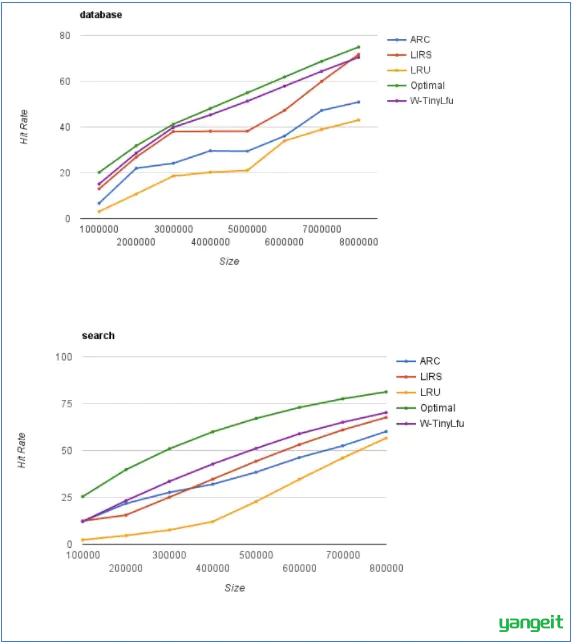
如图中数据库和搜索场景的结果展示,通过考虑就近程度和频率能大大提升LRU的表现。一些高级的策略,像ARC,LIRS和W-TinyLFU都提供了接近最理想的命中率。想看更多的场景测试,请查看相应的论文,也可以在使用simulator来测试自己的场景。
案例代码
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.6.2</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>5.1.10.RELEASE</version>
</dependency>
com.yange.config包
@Configuration
@EnableCaching
public class CacheConfiguration {
@Bean(name = "oneHourCacheManager")
public CacheManager oneHourCacheManager(){
Caffeine caffeine = Caffeine.newBuilder()
.initialCapacity(10) //初始大小
.maximumSize(11) //最大大小
.expireAfterWrite(1, TimeUnit.HOURS); //写入/更新之后1小时过期
CaffeineCacheManager caffeineCacheManager = new CaffeineCacheManager();
caffeineCacheManager.setAllowNullValues(true);
caffeineCacheManager.setCaffeine(caffeine);
return caffeineCacheManager;
}
}
@Cacheable(cacheManager = "oneHourCacheManager", value = "yange", key = "#{name}")
public Person getPersonByName(String name){
// 可以自定义代码,比如拿着 name 去数据库中查询此人的信息
}
@Cacheable可以注解在某个类上,也可以注解在某个方法上,分别表示该类的所有方法都要使用缓存,该方法使用缓存。
- 比如上述代码,表示使用一个名字为 yange 的缓存,
- 如果缓存不存在,springboot 就会自动创建一个缓存,此缓存是由 Bean 名字为 oneHourCacheManager 的管理器所管理,当 Person getPersonByName(String name) 方法被调用时,参数 name 作为 key,先去缓存中查询 name 这个 key是否存在,
- 如果存在,则直接根据 key 获取到 Person 实例对象,作为 getPersonByName(String name) 方法的返回值,
- 如果不存在,则执行 getPersonByName(String name) 方法,从数据库中去查询,将查询到的 Person 实例对象存储进缓存中,再将 Person 对象实例作为方法的返回值。
- 如果缓存不存在,springboot 就会自动创建一个缓存,此缓存是由 Bean 名字为 oneHourCacheManager 的管理器所管理,当 Person getPersonByName(String name) 方法被调用时,参数 name 作为 key,先去缓存中查询 name 这个 key是否存在,